








I. 서 론
지난 2010년, 의료법 개정을 통해 의료기관에서 의사, 한의사, 치과의사의 상호교차 고용이 허용되었고 한의과에서는 ICD-10(국제표준질병사인분류)에 근거한 KCD-6(한국표준질병사인분류)를 주요 진단으로 적용함에 따라 한의과와 의과가 같은 진단명을 사용하여 한의 의료기관 이용 환자들이 국가 통계에 공식 집계되기 시작하였다. 이러한 의료체계의 변화에 따라 협진 이용 빈도는 증가할 것으로 예측되었고, 협진에 의한 질환별 이용 현황과 치료별 비용 효과 등에 대한 다양한 분석을 할 수 있는 환경이 마련되었다. 하지만, 의료기관의 동시 개설이 가능함에도 불구하고, 주된 치료에만 급여가 적용되고 후행 진료는 비급여로 진행되어 환자의 부담은 가중되고 대부분의 협진이 한의 치료를 위한 의과의 진단⋅검사 의뢰 수준으로 시행되어 진정한 의미의 협진이 시행되지 않는 한계를 지니고 있었다.
이에 정부는 한의약 보장성 강화를 위해 의⋅한 협진 활성화가 필요하다는 판단에 따라 ‘의⋅한 협진 시범사업’을 시행하였다. 2016년 7월부터 동일 날 동일 상병 협진의 중복진료에 대한 건강보험 보장성을 지원해주는 1단계 시범사업을 시행하였고, 2017년 11월부터는 협진 수가를 산정하여 2단계 시범사업을 시행하였으며, 2019년 이후 3단계 시범사업을 통해 협진 의료기관을 인증하고, 다빈도 협진 질환들에 대한 협진 수가를 개발하여 제도화를 목표로 하고 있다1.
앞서 의⋅한 협진 2단계 시범사업 시행 이후, 이에 관한 평가 연구를 통해 협진 기관의 시설, 인력, 협진 프로토콜 평가 기준 등 인증기준 개발을 목적으로 하는 3단계 시범사업의 근거를 마련하여 방향성을 제시한 바 있다.
본 연구는 ‘의⋅한 협진 3단계 시범사업 다빈도 질환의 후향적 진료기록 분석연구’를 위한 예비연구로, 실제 임상 상황에 맞게 연구모형과 증례기록서가 설계되었는지 확인하고 각 기관에서 의견을 수렴하기 위한 단계이다. 수집한 기초자료를 바탕으로 향후 시행될 본 연구 적용 가능성을 확인하기 위한 타당성을 조사하였고, 본 연구 계획서 작성에 반영할 수정 및 보완사항과 통계모형 설정에 필요한 지견을 얻었기에 보고하는 바이다.
II. 연구 대상 및 방법
1. 연구 설계
의⋅한 협진 3단계 시범사업 참여기관 70개 중 예비연구에 참여가능한 7개 기관을 대상으로 하였다. 예비연구 이전에 참여기관의 연구 담당자와 질환 자문가를 통해 각 질환군 별 평가지표와 평가주기를 확정하였으며, 의⋅한 협진 3단계 시범사업의 후향적 예비연구 연구계획서 및 증례기록서를 개발하였다. 이를 통해 의⋅한 협진 3단계 시범사업 급여 대상 상병코드에 해당하는 전 질환군에 대해서 협진군과 비협진군으로 분류하여 기관별 질환군 및 협진 현황을 파악하고 치료 효과를 기록하여 본 연구의 실현 가능성을 확인하고자 병원 기반 환자군 다기관 후향적 차트리뷰 조사연구를 시행하였다.
2. 연구 대상
의⋅한 협진 3단계 시범사업 참여기관 중 예비연구에 참여가능한 7개 기관에서 시범사업 실시일인 2019년 10월 15일 이후 2019년 12월 31일까지 외래로 내원하거나 입원하여 진료를 받은 환자가 대상이며, 협진을 받은 환자(협진군)와 협진을 받지 않고 단독치료만을 받은 환자(비협진군) 전수로 하며 양군의 피험자 수는 경쟁적으로 모집하였다. 모집된 환자 중 선정 기준에 부합하고 제외 기준에 해당되지 않는 환자가 연구 대상으로 등록되었다. 선정 기준과 제외 기준은 다음과 같다.
3. 데이터 수집, 측정 및 관리
데이터는 각 기관별로 IRB 승인 후, 의⋅한의 협진 모니터링 센터에서 작성한 증례기록서에 해당하는 환자의 작성된 의무기록 및 자료를 각 기관의 규정에 따라 행정부서로부터 전달받아 해당 연구담당자들이 증례기록서를 작성하는 방법을 사용하였다. 또한 필수 결과지표가 누락된 것이 확인되면 피험자에서 제외하였다.
증례기록서는 환자의 이름 영문 이니셜, 인구사회학적 특성, 과거력, 주상병, 보험 종류, 거주지역, 초진일 및 재진일, 회복 정도에 대한 정보를 포함하고 있다. 인구사회학적 특성에는 연령과 성별이 포함되며, 회복 정도에 대한 지표로는 Numerical Rating Scale(NRS), 질환별 다빈도 평가지표 점수, 치료 횟수, 협진 횟수, 입원 시 입원 기간이 포함된다.
회복 정도에 대한 지표는 작성된 의무기록지를 활용했으며, 질환별 다빈도 평가지표로 치매에는Mini Mental State Examination-Korea(MMSE-K), 뇌졸중에는 Korean Version of Modified Barthel Index(K-MBI), 안면마비에는 House-Brackmann grading system, Yanagihara’s grading system 등이 사용되었고 기타 Visual Analogue Scale(VAS), National Institutes of Health Stroke Scale(NIHSS) 등의 지표를 통해 평가된 자료를 수집하였다.
본 연구는 후향적 관찰 연구로서 치료 내용에 대해 정해진 중재가 없어, 치료 내용은 수집하지 않았다.
4. 통계 분석 방법
치료 전 협진군과 비협진군의 치료 전 상태의 동일성을 검증하기 위하여 인구학적 특성에 대해 연속형 변수는 independent t-test를 이용하고, 범주형 변수는 chi-square test를 이용하여 통계적 가설검정을 수행하였다.
치료 후 상병 별, 협진과 비협진 별로 데이터를 구분하여 성과를 비교하였으며, 그중 표본 수를 고려하여 비교 가능한 상병대분류 별 성과비교를 시행하였다. 협진군과 비협진군 간의 유의한 교란요인 차이가 없다면 재방문 시점의 유효성 평가변수(NRS 등)의 차이를 independent t-test를 이용하여 통계학적 유효성을 비교하고, 차이가 있다면 교란요인들의 보정을 위해 평가변수의 분포를 고려한Generalized Estimating Equation(GEE) 모형을 이용하여 두 군 간의 통계적 차이를 확인하고자 하였다. 보정방법으로는(i) 성향점수(Propensity Score, PS) 기반의 공변량 보정(ii) 성향점수 기반의 매칭(iii) 성향점수 기반의 Inverse Probability Treatment Weight(IPTW)를 사용하였다.
로지스틱 회귀모형 기반의 PS 추정을 위한 변수로는 성별, 나이, 보험구분, 과거력(고혈압, 당뇨, 고지혈증, 기타), 거주지역, 치료횟수, 입원 기간이 있으며, PSM(PS Matching)을 사용하면서 nearest neighborhood method을 이용해 매칭시켰다. 매칭된 군 간 균형을 확인하기 위해ASD(Absolute Standardized Difference) 값을 활용하였으며, 그 기준은 0.25로 삼았다. 또한, follow-up에 따른 변화 및 그룹 간 차이는 GEE 모형을 활용하여 확인하였다.
통계분석은 ‘R version 3.6.1’ software를 사용하였고, PS Matching은 ‘Matchit’ package, GEE model은 ‘geepack’ package를 활용하였다.
추가로 연구 과정 중 기관 관계자 및 연구원들과 오프라인 회의를 통해 연구의 개선방향과 문제점에 대해 토의하였다.
III. 결 과
1. 전체 현황
의⋅한 협진 3단계 시범사업 참여기관 7개 기관에서 수집한 환자데이터는 총 182건이며, 상병별, 협진과 비협진 별로 데이터를 구분한 결과는 다음과 같다(Table 1, 2). 협진군과 비협진군의 표본 수를 고려할 때, 비교가 가능한 상병 대분류는 M군과 S군이었다.
Table 1
Overall Status of Collaboration and Non-Collaboration by Institution and Disease Code
|
Disease code Institution ID |
M | S | G | I | K | F | Total | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C* | NC† | C | NC | C | NC | C | NC | C | NC | C | NC | |||
| 20 | 0 | 0 | 0 | 0 | 0 | 13 | 0 | 5 | 0 | 1 | 0 | 1 | 20 | |
| 03 | 0 | 5 | 0 | 0 | 0 | 7 | 0 | 4 | 0 | 0 | 0 | 0 | 16 | |
| 24 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | |
| 14 | 16 | 18 | 12 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 52 | |
| 25 | 15 | 21 | 10 | 16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 62 | |
| 49 | 3 | 4 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | |
| 15 | 13 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 20 | |
| C | NC | 48 | 49 | 27 | 25 | 0 | 20 | 0 | 9 | 1 | 2 | 0 | 1 | 182 |
| Total | 97 | 52 | 20 | 9 | 3 | 1 | 182 | |||||||
Table 2
Status of Collaboration and Non-Collaboration by Disease Code
| Disease code | Total | Non-collaboration group | Collaboration group | |||
|---|---|---|---|---|---|---|
| n* | % | n | % | n | % | |
| M | 96 | 100.0 | 49 | 51.0 | 47 | 49.0 |
| S | 51 | 100.0 | 25 | 49.0 | 26 | 51.0 |
| G | 20 | 100.0 | 19 | 95.0 | 1 | 5.0 |
| I | 8 | 100.0 | 8 | 100.0 | 0 | 0.0 |
| K | 3 | 100.0 | 2 | 66.7 | 1 | 33.3 |
| F | 1 | 100.0 | 1 | 100.0 | 0 | 0.0 |
2. 비교 가능한 상병대분류 M군, S군
1) 성과 변수
NRS를 성과변수로 활용하였다. 기타 MMSE-K, K-MBI, NIHSS 등이 M군과 S군의 모든 조사 시점에서 조사되지 않았기 때문이다. 각 상병 별로NRS는 3차 방문부터 조사되는 대상이 없어 2차 방문 조사 자료까지만 활용되었다(Table 3).
Table 3
Follow up of Outcome Measure
| Disease code | Outcome measure | Visit | Number of patients | |
|---|---|---|---|---|
| Non-collaboration group | Collaboration group | |||
| M | NRS* | 1 | 49 | 47 |
| 2 | 49 | 47 | ||
| 3 | 3 | 0 | ||
| S | NRS | 1 | 25 | 26 |
| 2 | 25 | 26 | ||
| 3 | 0 | 0 | ||
2) 대상자 특성
상병대분류인 M군과 S군의 대상자 특성을 분석한 결과는 다음과 같다(Table 4, 5). 연속형 변수는independent t-test를 이용하고, 범주형 변수는 chi-square test를 이용하여 p-value를 구하였다. M군은 변수 중 나이 및 입원기간이 협진군과 비협진군 간 통계학적으로 유의한 차이가 나타났으며, S군은 거주지역이 두 군 간 통계학적으로 유의한 차이가 나타났다.
Table 4
Baseline Characteristics of Disease Code : M
| Variable† | Total (n=96) | NC‡ (n=49) | C§ (n=47) | p-value | ||
|---|---|---|---|---|---|---|
| Sex | Male | 43 (44.8) | 22 (44.9) | 21 (44.7) | 1.00 | |
| Female | 53 (55.2) | 27 (55.1) | 26 (55.3) | |||
| Insurance | Health insurance | 95 (99) | 48 (98) | 47 (100) | 1.00 | |
| others | 1 (1) | 1 (2) | 0 (0) | |||
| Past history | High blood pressure | - | 79 (82.3) | 37 (75.5) | 42 (89.4) | 0.13 |
| + | 17 (17.7) | 12 (24.5) | 5 (10.6) | |||
| Diabetes | - | 91 (94.8) | 45 (91.8) | 46 (97.9) | 0.38 | |
| + | 5 (5.2) | 4 (8.2) | 1 (2.1) | |||
| Hyperlipidemia | - | 93 (96.9) | 46 (93.9) | 47 (100) | 0.26 | |
| + | 3 (3.1) | 3 (6.1) | 0 (0) | |||
| Others | - | 70 (72.9) | 32 (65.3) | 38 (80.9) | 0.14 | |
| + | 26 (27.1) | 17 (34.7) | 9 (19.1) | |||
| Residence | Metropolis | 47 (49.0) | 20 (40.8) | 27 (56.4) | 0.25 | |
| Small and medium sized city | 45 (46.8) | 27 (55.1) | 18 (38.3) | |||
| Rural area | 4 (4.2) | 2 (4.1) | 2 (4.3) | |||
| Age (years) | 47.3±15.7 | 50.9±15.1 | 43.7±16.2 | 0.03* | ||
| Treatment (number) | 6.5±7.2 | 7.2±8.5 | 5.7±5.8 | 0.31 | ||
| Hospital stay (days) | 3.1±6.5 | 5.0±8.8 | 1.2±4.2 | 0.01* | ||
Table 5
Baseline Characteristics of Disease Code : S
| Variable | Total (n=51) | NC† (n=25) | C‡ (n=26) | p-value | ||
|---|---|---|---|---|---|---|
| Sex | Male | 25 (49%) | 14 (56%) | 11 (42.3%) | 0.49 | |
| Female | 26 (51%) | 11 (44%) | 15 (57.7%) | |||
| Insurance | Health insurance | 47 (92.2%) | 21 (84%) | 26 (100%) | 0.11 | |
| Others | 4 (7.8%) | 4 (16%) | 0 (0%) | |||
| Past history | High blood pressure | - | 44 (86.3%) | 20 (80%) | 24 (92.3%) | 0.38 |
| + | 7 (13.7%) | 5 (20%) | 2 (7.7%) | |||
| Diabetes | - | 48 (94.1%) | 23 (92%) | 25 (96.2%) | 0.97 | |
| + | 3 (5.9%) | 2 (8%) | 1 (3.8%) | |||
| Hyperlipidemia | - | 48 (94.1%) | 24 (96%) | 24 (92.3%) | 1.00 | |
| + | 3 (5.9%) | 1 (4%) | 2 (7.7%) | |||
| Others | - | 41 (80.4%) | 20 (80%) | 21 (80.8%) | 1.00 | |
| + | 10 (19.6%) | 5 (20%) | 5 (19.2%) | |||
| Residence | Metropolis | 22 (43.1%) | 6 (24%) | 16 (61.5%) | 0.02* | |
| Small and medium sized city | 29 (56.9%) | 19 (76%) | 10 (38.5%) | |||
| Age (years) | 45.5±13.7 | 44.7±13.5 | 46.3±13.9 | 0.68 | ||
| Treatment (number) | 6.4±5.8 | 7.9±6.8 | 4.9±4.7 | 0.08* | ||
| Hospital stay (days) | 3.8±5.9 | 5.3±6.8 | 2.2±5.0 | 0.07* | ||
3) 성향점수(Propensity Score, PS) 분포
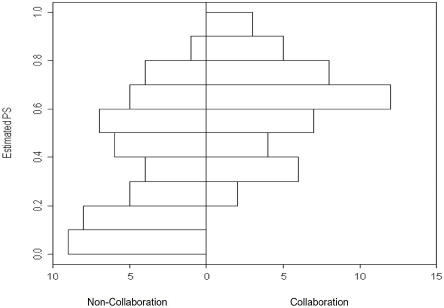
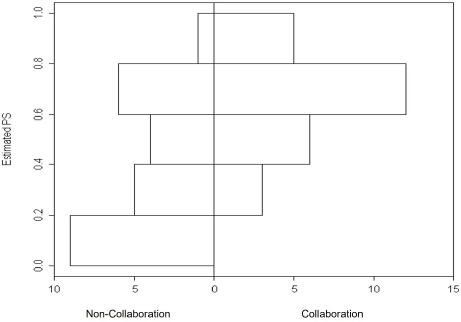
4) Matching 전후 그룹 간 균형
Table 6
Balance Between Groups Before and After Matching of Disease Code : M
| Variable† | Before matching | After matching | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NC‡ (n=49) | C§ (n=47) | p-value | ASD | NC (n=35) | C (n=35) | p-value | ASD | |||
| Sex | Male | 22 (44.9%) | 21 (44.7%) | 1.00 | 0.00 | 18 (51.4%) | 17 (48.6%) | 1.00 | 0.06 | |
| Female | 27 (55.1%) | 26 (55.3%) | 17 (48.6%) | 18 (51.4%) | ||||||
| Insurance | Health insurance | 48 (98%) | 47 (100%) | 1.00 | 0.20 | 35 (100%) | 30 (85.7%) | 1.00 | 0.00 | |
| Others | 1 (2%) | 0 (0%) | 8 (22.9%) | 5 (14.3%) | ||||||
| Past history | High blood pressure | - | 37 (75.5) | 42 (89.4) | 0.13 | 0.37 | 27 (77.1) | 30 (85.7) | 0.539 | 0.22 |
| + | 12 (24.5) | 5 (10.6) | 8 (22.9) | 5 (14.3) | ||||||
| Diabetes | - | 45 (91.8%) | 46 (97.9%) | 0.38 | 0.28 | 34 (97.1%) | 34 (97.1%) | 1.00 | 0 | |
| + | 4 (8.2%) | 1 (2.1%) | 1 (2.9%) | 1 (2.9%) | ||||||
| Hyperlipidemia | - | 46 (93.9%) | 47 (100%) | 0.26 | 0.36 | 35 (100%) | 35 (100%) | 1.00 | 0 | |
| + | 3 (6.1%) | 0 (0%) | 0 (0%) | 0 (0%) | ||||||
| Others | - | 32 (65.3%) | 38 (80.9%) | 0.14 | 0.36 | 26 (74.3%) | 27 (77.1%) | 1.00 | 0.07 | |
| + | 17 (34.7%) | 9 (19.1%) | 9 (25.7%) | 8 (22.9%) | ||||||
| Residence | Metropolis | 20 (40.8%) | 27 (56.4%) | 0.25 | 0.32 | 19 (54.3%) | 20 (57.1%) | 0.97 | 0.06 | |
| Small and medium sized city | 27 (55.1%) | 18 (38.3%) | 0.34 | 14 (40%) | 13 (37.1%) | 0.06 | ||||
| Rural area | 2 (4.1%) | 2 (4.3%) | 0.01 | 2 (5.7%) | 2 (5.7%) | 0 | ||||
| Age (years) | 50.9±15.1 | 43.7±16.2 | 0.03* | 0.46 | 48.9±15.1 | 45.7±15.8 | 0.34 | 0.21 | ||
| Treatment (number) | 7.2±8.5 | 5.7±5.8 | 0.31 | 0.21 | 4.7±4.1 | 5.4±5.5 | 0.54 | 0.14 | ||
| Hospital stay (days) | 5.0±8.8 | 1.2±4.2 | 0.01* | 0.55 | 2.2±4.2 | 1.7±4.9 | 0.64 | 0.11 | ||
Table 7
Balance Between Groups Before and After Matching of Disease Code : S
| Variable† | Before matching | After matching | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||
| NC‡ (n=25) | C§ (n=26) | p | ASD | NC (n=12) | C (n=12) | p | ASD | |||
| Sex | Male | 14 (56%) | 11 (42.3%) | 0.49 | 0.28 | 7 (58.3%) | 6 (50%) | 1.00 | 0.17 | |
| Female | 11 (44%) | 15 (57.7%) | 5 (41.7%) | 6 (50%) | ||||||
| Insurance | Health insurance | 21 (84%) | 26 (100%) | 0.11 | 0.62 | 12 (100%) | 12 (100%) | 1.00 | 0.00 | |
| Others | 4 (16%) | 0 | 0 | 0 | ||||||
| Past history | High blood pressure | - | 20 (80%) | 24 (92.3%) | 0.38 | 0.36 | 12 (100%) | 12 (100%) | 1.00 | 0.00 |
| + | 5 (20%) | 2 (7.7%) | 0 | 0 | ||||||
| Diabetes | - | 23 (92%) | 25 (96.2%) | 0.97 | 0.18 | 12 (100%) | 12 (100%) | 1.00 | 0.00 | |
| + | 2 (8%) | 1 (3.8%) | 0 | 0 | ||||||
| Hyperlipidemia | - | 24 (96%) | 24 (92.3%) | 1.00 | 0.16 | 12 (100%) | 12 (100%) | 1.00 | 0.00 | |
| + | 1 (4%) | 2 (7.7%) | 0 | 0 | ||||||
| Others | - | 20 (80%) | 21 (80.8%) | 1.00 | 0.02 | 9 (75%) | 10 (83.3%) | 1.00 | 0.00 | |
| + | 5 (20%) | 5 (19.2%) | 3 (25%) | 2 (16.7%) | ||||||
| Residence | Metropolis | 6 (24%) | 16 (61.5%) | 0.02* | 0.82 | 5 (41.7%) | 6 (50%) | 1.00 | 0.17 | |
| Small and medium sized city | 19 (76%) | 10 (38.5%) | 0.82 | 7 (58.3%) | 6 (50%) | 0.17 | ||||
| Age (years) | 44.7±13.5 | 46.3±13.9 | 0.68 | 0.12 | 45.9±13.6 | 45.3±14.1 | 0.92 | 0.04 | ||
| Treatment (number) | 7.9±6.8 | 4.9±4.7 | 0.08* | 0.51 | 4.8±4.9 | 5.9±5.4 | 0.58 | 0.21 | ||
| Hospital stay (days) | 5.3±6.8 | 2.2±5.0 | 0.07* | 0.52 | 1.8±3.2 | 2.3±5.5 | 0.79 | 0.11 | ||
5) GEE 모형
M군과 S군에서 GEE 모형적합 결과는 다음과 같다(Table 8, 9). 시간의 흐름에 따른 NRS는 통계학적으로 유의하게 감소하고, 협진여부에 따른NRS 차이는 유의하지 않으며, 시간의 흐름에 따른 협진군과 비협진군의 유의한 NRS 차이는 없다.
Table 8
Results of Fit Test for GEE Model in Disease Code : M
| Variable | Matching | Adjusted | IPTW‡ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| β̂ | s.e. | p | β̂ | s.e. | p | β̂ | s.e. | p | |
| Time† | -0.123 | 0.024 | <.001* | -0.071 | 0.016 | <.001* | -0.063 | 0.015 | <.001* |
| Collaboration or not (ref. non-collaboration) | 0.379 | 0.367 | 0.302 | 0.392 | 0.347 | 0.260 | 0.312 | 0.316 | 0.320 |
| Time X Collaboration or not | 0.029 | 0.028 | 0.300 | -0.001 | 0.023 | 0.960 | -0.003 | 0.022 | 0.890 |
Table 9
Results of Fit Test for GEE Model in Disease Code : S
| Variable | Matching | Adjusted | IPTW‡ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| β̂ | s.e. | p | β̂ | s.e. | p | β̂ | s.e. | p | |
| Time† | -0.157 | 0.024 | <.001* | -0.094 | 0.027 | <.001* | -0.091 | 0.028 | <.001* |
| Collaboration or not (ref. non-collaboration) | 0.518 | 0.507 | 0.310 | 0.326 | 0.384 | 0.396 | 0.713 | 0.380 | 0.061 |
| Time X Collaboration or not | 0.044 | 0.055 | 0.430 | 0.020 | 0.037 | 0.584 | 0.004 | 0.039 | 0.923 |
IV. 고찰 및 결론
본 예비연구는 의⋅한 협진 3단계 시범사업 참여기관 70개 중 7개 기관을 연구 대상으로 선정하여 시범사업 급여 대상 상병코드에 해당하는 전 질환군에 대해서 협진군과 비협진군으로 분류하고 후향적 차트리뷰 조사연구를 시행하였다. 예비연구의 결과를 토대로 증례기록서가 실제 임상 상황에 맞게 개발되었는지 수정 및 보완사항을 확인하였고, 통계모형을 본 연구에 적용이 가능한지 타당성을 조사하였다.
먼저, 협진군과 비협진군의 표본 수를 고려할 때 비교가 가능한 상병대분류는 M, S, G, I, K, F군 중 M군과 S군에 그쳤다. 협진군 비율이 G군은 5%, K군은 33%, I군과 F군은 0%으로 협진군에 대한 데이터가 부족하여, 비교 분석하는데 제외되었다. 이는 본 연구에서 모집 기간과 참여 기관 수가 늘어나면 보완될 수 있을 것으로 사료된다.
또한, 상병대분류 I, G코드는 비협진군의 데이터만 수집되었는데, 이는 예비연구를 단기간 동안 시행하여 협진군의 데이터가 충분히 수집되지 않았고, 참여 기관마다 질환군의 평가지표가 동일하지 않아 자료가 결측된 것으로 사료된다. 전 등의 연구2에 따르면 신경계 질환(G00-G99)과 순환계 질환(I00-I99)이 의ㆍ한 협진 연구에서 많이 다루고 있는 질환군으로서, 추후 본 연구에서는 데이터의 필요성이 높은 해당 질환군의 환자를 모집하기 위한 방안을 수립할 필요가 있다.
예비연구에서는 M군과 S군의 협진군과 비협진군 간 유의한 교란요인이 있어 보정을 위해 성향점수를 사용하였다. 다차원인 공변량들을 성향점수라는 일차원 점수로 차원을 축소하는 방법으로서, 관찰된 교란 요인들의 균형을 맞추어 무작위 배정과 유사한 상황을 만든 이후에 관심 있는 치료효과를 추정하기 위해 사용하는 방법이다3. 이 점수를 기준으로 동일한 성향점수를 갖지만 치료효과가 다르게 나오는 표본을 매칭하여, 어떠한 요인들이 영향을 미쳐 다른 결과를 도출해내는지 분석할 수 있다. 매칭은 nearest neighborhood method를 사용하였고, 매칭된 그룹 간 균형을 확인하고자 통계적 검정 뿐만 아니라 표본 수에 의존하지 않는 통계량인 ASD를 활용하였다. 그리고 매칭된 대상자를 바탕으로 GEE 모형을 사용하여 시간의 흐름에 따른 변화와 협진군과 비협진군 간의 치료 효과의 변화 차이를 파악하였다.
ASD는 일반적으로 0.1 이하를 권고하긴 하나, 명확하게 정해진 기준은 없으며 많은 연구들에서 실제로 0.2, 0.25, 0.3 등을 기준으로 사용하기도 하고, PS 매칭에 있어서는 알맞은 변수 간 균형을 위해 ASD 값은 0.25보다 작거나 같도록 설정해야 한다고 보고된 바 있다4,5. 본 예비연구는 0.1을 기준으로 맞추려고 하였으나, 그 기준을 충족하기 위해서는 그룹별 30명 이상의 대상자가 선정되어야 한다. 현재 데이터로는 30명 미만이므로 0.25를 기준으로 사용하였다. 예비연구에서는 대상자의 수가 적어 0.25를 기준으로 사용하였으나, 추후 본 연구에서는 협진군과 비협진군 각각 최소 30명 이상의 대상자 데이터가 수집된다면 ASD를 0.1로 삼아 치료 효과의 유의성을 판단할 수 있을 것으로 사료된다. 또한, M군과 S군의 성향점수 추정 시 어느 정도 높은 적합도(C-statistics)를 보이지만, 0.8 이상으로 높이기 위해서는 이미 고려하였던 성별, 나이, 보험구분, 과거력, 거주지역, 치료횟수, 입원 기간 이외에 추가 교란 요인의 고려가 필요한 것으로 사료된다.
GEE모형 분석 결과, 시간의 흐름에 따른 협진군과 비협진군의 유의한 NRS 차이를 보이지 않았다. 이는 부족한 표본으로 인해 검정력이 낮아 유의하지 않은 결과가 산출된 것으로 보이며, 본 연구에서 충분한 표본 수를 확보한다면 유의한 차이가 나타날 가능성이 있다. 또한, 예비연구에서는 데이터 수집일에 가장 가까운 마지막 진료일을 재진일로 설정하여, 초진일과 재진일의 차이가 짧게는 1일, 길게는 69일로 편차가 컸다. 이는 후향적 연구의 한계로서 추적관찰 기간의 편차가 크다는 점을 본 연구의 분석 모형에 반영하여야 할 것이다.
본 예비연구를 통해 연구 모형과 증례기록서가 실제 임상 상황에서 적용 가능한지 확인하였고, 이를 바탕으로 추후 다빈도 협진 질환에 대한 후향적 진료기록 분석연구의 진행 방향을 설정하는데 참고자료로서 삼고자 한다.


